My Computer Made New Pokemons
How computers learn to generate content using Generative Adversarial Networks.

The painting looks impressive, right? Well, it is, but not in the human sense of the word. What do I mean by this? Well, the art piece you are looking at is generated by a computer 🤯! How on earth are computers getting so good at coming up with art?
For one, you aren’t alone, the art auctioning company. Christie’s sold a portrait for $432,000 that had been generated by a GAN, based on open-source code written by Robbie Barrat, a recent high-school graduate.
While it has caught the attention of mainstream media, it has also been considered a massive development in the machine learning community with Facebook’s Head of AI, Yann LeCunn calling it

“The coolest idea in deep learning in the last 20 years.”
Cops And Robbers
Imagine there is a world in which there is a robber who is trying to make counterfeit money (fake money). He tries to make a replica of real bills to make a lot of money. Then, there are the police who are aware of the robber’s counterfeiting business and wants to stop the robber at all costs. So, the police go through all the money bills at the end of each night, checking which one is real and which one is fake. Since the robber was new to the counterfeiting business, he made a poor replica that was easily caught by the police.
The next day, the robber got to work, making more replicas, this time more refined and better quality. However, once again, the police were able to spot the difference between a fake bill when comparing it to a real one. Then, the robber once again improves the design of his counterfeit bill to make it look very much like an actual bill. However, the police are once still able to spot differences between the fake and the real. This process of generation and inspection goes on until the police are unable to distinguish the counterfeit bills from the real one.
This never-ending process that the robber and police are engaged in reflects the process that computers use to generate fake content that looks real. They do this through a Generative Adversarial Network or GAN for short. In the case of GANs, a generative model acts as the robber while the discriminator model acts as the police.
Generative Adversarial Networks can be seen as a hybrid approach to supervised and unsupervised learning as the generative model is unsupervised while the discriminator model relies on supervised learning.
Generator Model
The generator takes in a fixed-length input vector, which is randomly drawn from the Gaussian distribution. This random vector acts as a seed for the generator to produce a random piece of content. These vectors exist within a vector space whose points form a compressed representation of the original data distribution.
This vector space is also referred to as the latent space consisting of latent variables. These latent variables cannot be directly observed and are random variables. The generator chooses a group of hidden variables in the compressed hidden space to use as input for the generator to create new and unique content. Essentially, a random vector of numbers called latent variables are the input the generator model to output some unique content (image, music. text, etc.)
Don’t worry If that didn’t fully make sense. It is a very technical concept relating to statistics. To learn more about latent variables in relation to generative modelling, check out this research paper: Latent Variable Modeling for Generative Concept Representations and Deep Generative Models
Discriminative Model
The discriminator is a simple classification model that is fed a dataset with a mixture of real content and fake content generated by the generator. Its sole purpose is to output whether a given piece of content is real or fake. Depending on the success or failure of the model’s prediction, backpropagation updates the weights and biases within the network. As the generator produces better fakes, the discriminator gets better at distinguishing fakes from real content.
Check out the original GAN Research Paper to learn more:https://arxiv.org/pdf/1406.2661.pdf
Putting it Together
Now that we have understood both components of a GAN, we can put them together. As for the structure of the GAN, it is quite straightforward. Pass a random vector into the generator, which then spits out fake content. That artificially generated content is passed to the discriminator along with an additional dataset of real content. The discriminator predicts whether each piece of content is real or fake, and both the generator and discriminator are updated using backpropagation.

While both the generator and discriminator have different goals (different loss functions), they cooperate (in a unique sense of the word) to accomplish the goal of producing better quality content, much like an actor-critic model. If the discriminator achieves poor performance, the generator will also achieve poor performance.
From a game theory perspective, the discriminator and generator are two-player competing against each other. The game itself is zero-sum in nature, meaning that the gain of one player results in or is caused by the direct loss of the other player. At the peak of both players collectively, the generator produces perfect replicas leaving the discriminator is unsure whether the content is fake or note (50% prediction for real and fake).
Making Fake Pokémon’s!

For this project, I will be using the PyTorch framework and a Pokémon Image Dataset on Kaggle. In this project, I will be creating a Deep Convolutional GAN to generate fake Pokémon images. A DCGAN is a type of GAN that excels at producing image content as it contains Convolutional Layers.
Training Parameters
To begin, we will need to define some inputs and parameters for setting the neural network architectures as well as training.
Input Data
Here is a sample of the Pokémon images that make up the dataset. For my model, I decided to downscale the images to 64 x 64 for an efficient process and data normalization. A DCGAN prefers a three-channel input (RGB); however, since the dataset had a transparent background, it had four channels (RGBA — A is referring to the alpha channel). It is recommended that you convert these to RGB images for improved performance; however, I lazily decided to skip this step 😁.

Generator
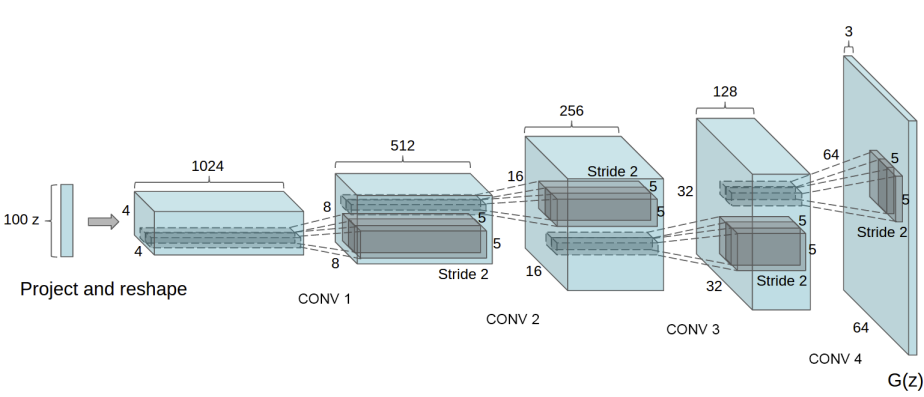
Now that we have our data, we can start off defining the architecture for the generator model. Given the latent vector as input, the generator outputs an image matching the images in the dataset 3 x 64 x 64. The model itself has five convolutional layers for making the image and its layers. Each convolutional layer is followed by batch normalization to improve the efficiency and stability of the network. Also, the model uses ReLU as its activation function (except for the final being a tan hyperbolic function). It is important to note that the network is initialized with a random set of weights and biases, resulting in noise.
Discriminator
The discriminator architecture is very similar to the generator as it has the same overall structure. The main difference is that the LeakyReLU and Sigmoid activation functions are used. Instead of suing convolutional layers that produce content, convolutional layers are used for classification. Similar to the generator, the discriminator is also initialized with a random set of weights and biases.
Loss Functions and Optimizers
The loss function used is the BCELoss function in PyTorch, which is a Binary Cross-Entropy Loss function. This loss function is optimal loss function for targets (output) between 0 (fake) and 1 (real), making it practical for our model.
For both networks, we will be using Adam Optimizers from PyTorch and is an adaptive learning rate optimization algorithm.
Training Time!
The time has come to put our GAN to work and initialize the training process. To do, we must define the generator and discriminator loss (this involves some math which I will skip for simplicity’s sake). Once we set up the training loop, we can just let the loop run for the number of epochs we defined earlier. I trained my model for 2500 epochs/iterations.
The Results Are In!
Well, the results were interesting, to say the least. I particular found it interesting how many of the fake Pokémon’s looked the same. But, I will let you be the judge of the quality of the fakes. I think it is pretty interesting, and I can see a couple of the fakes serving as inspiration for legitimate future Pokémon’s. The most interesting is the variation of Pokémons between various epochs or iterations of the GAN.
 Results of the training process over 2500 iterations (every frame is recorded every 100 iterations).
Results of the training process over 2500 iterations (every frame is recorded every 100 iterations).
You can check out the Google Colab Interactive Notebook to train the GAN yourself and make some tweaks!
TL;DR
- Computers generate artificial content using a Deep Learning network called Generative Adversarial Networks (GANs)
- GANs have a generator (creates fake content) and a discriminator (identifies whether the content is fake)
- DCGANs are a particular type of GAN network that excels at creating image content (like Pokémons)